I gave this simple reasoning prompt to 30+ AI models. Here’s what happened ![]()
Prompt:
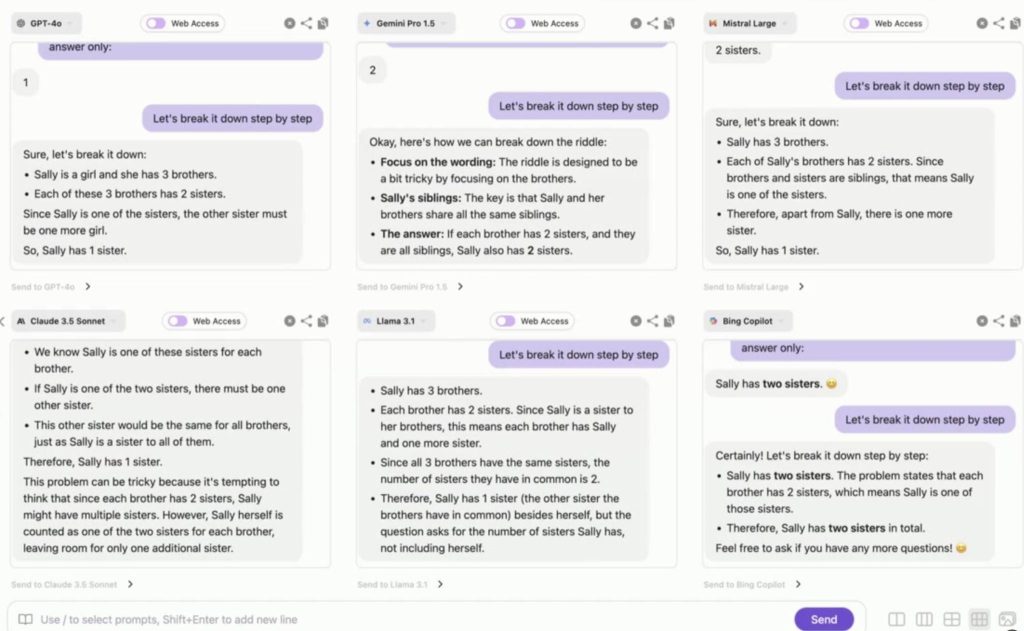
Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have? Let’s think step by step.
![]() Correct answer: 1
Correct answer: 1
(Sally is 1 sister. Each brother has 2 sisters total — Sally + one other.)
But when I ran this through all the top models using Admix.software, the results were wild. Most models failed a basic logic test.![]() Models That Got It Right (Only 2 of 30+):
Models That Got It Right (Only 2 of 30+):
- GPT-4 (OpenAI)
- ReMM SLERP L2 (13B)
These models reasoned properly and concluded Sally has just 1 sister.
Models That Said 6 Sisters (Majority fail group):
They misunderstood that “each brother has 2 sisters” means 6 total. But it’s the same 2 sisters shared!
- GPT-3.5 (all variants) Claude Instant v1 Claude v1, v1.2, v2 Code Llama (7B, 13B, 34B) Falcon (7B, 40B) PaLM 2 Bison (all) MPT-Chat (7B, 30B) Guanaco (33B, 65B) Qwen Chat Platypus 2 Luminous Base / Extended / Supreme Koala (13B) Command series (light, nightly) Vicuna (all variants) Alpaca 7B Airoboros L2 70B Chronos Hermes 13B RedPajama-INCITE Pythia, MythoMax, Dolly Jurassic 2 (Lite/Mid)
![]() Some even went as far as saying:
Some even went as far as saying:
“Sally has 24 sisters” (Jurassic 2 Light)
“Sally has 12 sisters”
“Sally has 0 sisters” (Guanaco 13B)
“Sally has 9 sisters” (Luminous Extended Control)
Why This Matters:
We’re entering a world where AI helps us write code, interpret data, and make decisions.
But if they can’t pass a basic riddle… are you really trusting the right model?
Use a platform like Admix.software
— it lets you compare up to SIX AI models side-by-side on any prompt.
You’ll quickly see which models actually reason… and which just make things up.